High performance computing tutorial, with checklist and tips to optimize cluster usage
3 likes4,934 views

Introduction to high performance computing, what is it, how to use it and when to use what. Provides a detailed checklist how to build pipelines and tips to optimize cluster usage and reduce waiting time in queue. It also provides a quick overview of resources available in Compute Canada.


![Raamana What is [not] HPC? ✓ Simply a multi-user, shared and smart batch processing system ✓ Improves the scale & size of processing significantly ✓ With raw power & parallelization ✓ Thanks to rapid advances in low cost micro-processors, high-speed networks and optimized software ✓ Imagine a big bulldozer! ✘ does not write your code! ✘ does not debug your code! ✘ does not speed up your code! ✘ does not think for you,
or write your paper! 3Raamana](https://image.slidesharecdn.com/hpcbasicsraamana25jan2018rotmanbaycresttorontonoanim-180125210248/85/High-performance-computing-tutorial-with-checklist-and-tips-to-optimize-cluster-usage-3-320.jpg)






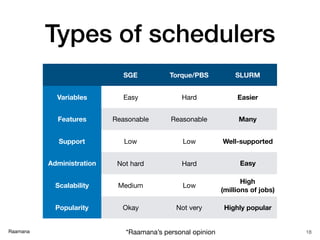

![Raamana Resource specification 20 Resource SLURM SGE number of nodes -N [min[-max]] N/A number of CPUs -n [count] -pe [PE] [count] memory (RAM) --mem [size[units]] -l mem_free=[size[units]] total time (wall clock limit) -t [days-hh:mm:ss] OR -t [min] -l h_rt=[seconds] export user environment --export=[ALL | NONE | variables] -V naming a job (important) --job-name=[name] -N [name] output log (stdout) -o [file_name] -o [file_name] error log (stderr) -e [file_name] -e [file_name] join stdout and stderr by default, unless -e specified -j yes queue / partition -p [queue] -q [queue] script directive (inside script) #SBATCH #$ job notification via email --mail-type=[events] -m abe email address for notifications --mail-user=[address] -M [address] Useful glossary: https://www.computecanada.ca/research-portal/accessing-resources/glossary/](https://image.slidesharecdn.com/hpcbasicsraamana25jan2018rotmanbaycresttorontonoanim-180125210248/85/High-performance-computing-tutorial-with-checklist-and-tips-to-optimize-cluster-usage-20-320.jpg)
![Raamana Node specification 21 Resource SLURM restrict to particular nodes --nodelist=intel[1-5] exclude certain nodes --exclude=amd[6-9] based on features (tags) --constraint=“intel&gpu” to a specific partition or queue --partition intel_gpu based on number of cores/threads --extra-node-info=<sockets[:cores[:threads]]> type of computation --hint=[compute_bound,memory_bound,multithread] contiguous --contiguous CPU frequency --cpu-freq=[Performance,Conservative,PowerSave] Useful glossary: https://www.computecanada.ca/research-portal/accessing-resources/glossary/](https://image.slidesharecdn.com/hpcbasicsraamana25jan2018rotmanbaycresttorontonoanim-180125210248/85/High-performance-computing-tutorial-with-checklist-and-tips-to-optimize-cluster-usage-21-320.jpg)



















































More Related Content
What's hot (20)
Similar to High performance computing tutorial, with checklist and tips to optimize cluster usage (20)


















Recently uploaded (20)



![Anti-Riot_Drone_Phase-0(2)[1] major project.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/anti-riotdronephase-021-250421082124-7a2c9000-thumbnail.jpg?width=560&fit=bounds)
![Anti-Riot_Drone_Phasmajorpte-0(2)[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/anti-riotdronephase-021-250421082630-125da45c-thumbnail.jpg?width=560&fit=bounds)















High performance computing tutorial, with checklist and tips to optimize cluster usage
- 1. Introduction to high performance computing: what, when and how? Pradeep Reddy Raamana crossinvalidation.com
- 2. Raamana • Self-explanatory! • process a batch of jobs, in sequence! • non-interactive, to reduce idle time. • let’s face it: humans are slow!! • Reduces startup & shutdown times, when run separately. • Efficient use of resources (run when systems are idle) Batch processing 2
- 3. Raamana What is [not] HPC? ✓ Simply a multi-user, shared and smart batch processing system ✓ Improves the scale & size of processing significantly ✓ With raw power & parallelization ✓ Thanks to rapid advances in low cost micro-processors, high-speed networks and optimized software ✓ Imagine a big bulldozer! ✘ does not write your code! ✘ does not debug your code! ✘ does not speed up your code! ✘ does not think for you, or write your paper! 3Raamana
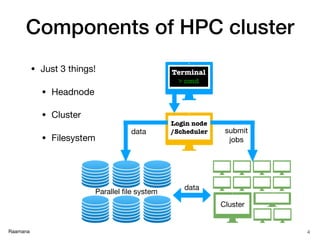
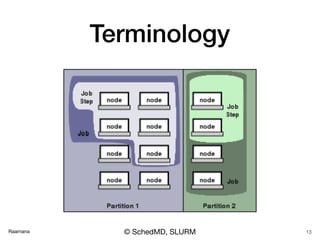
- 4. Raamana Components of HPC cluster Login node /Scheduler Terminal > cmd Cluster Parallel file system submit jobs data data • Just 3 things! • Headnode • Cluster • Filesystem 4
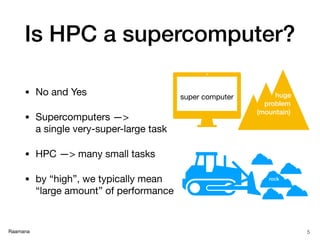
- 5. Raamana Is HPC a supercomputer? • No and Yes • Supercomputers —> a single very-super-large task • HPC —> many small tasks • by “high”, we typically mean “large amount” of performance 5 huge problem (mountain) super computer rock
- 6. Raamana Benefits of HPC cluster • Cost-effective • Much cheaper than a super-computer with the same amount of computing power! • When the supercomputer crashes, everything crashes! • When a single/few nodes in HPC fail, cluster continues to function. • Highly scalable • Multi-user shared environment: not everyone needs all the computing power all the time. • higher utilization: can accommodate variety of workloads (#CPUs, memory etc), at the same time. • Can be expanded or shrunk, as needed. 6
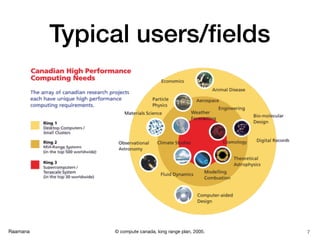
- 7. Raamana Typical users/fields 7© compute canada, long range plan, 2005.
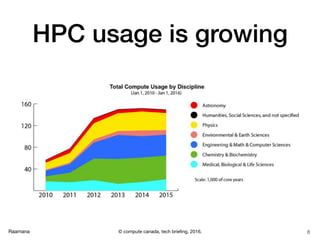
- 8. Raamana HPC usage is growing 8© compute canada, tech briefing, 2016.
- 9. Raamana Actual SharcNet Cluster: Graham Installed May 2017 9© Graham/Compute Canada
- 10. Raamana 10© Pinterest / Reddit / Google
- 11. Raamana Scheduler • Allocates jobs to nodes (i.e. time on resources available) • Applies priorities to jobs, according to policies and usage • Enforces limits on usage (restricts jobs to its spec) • Coordinates with the resource manager (accounting etc) • Manages different queues within a cluster • customized with different limits on memory, CPU speed and number of parallel tasks etc. • Manages dependencies (different “steps” within the same job)! 11
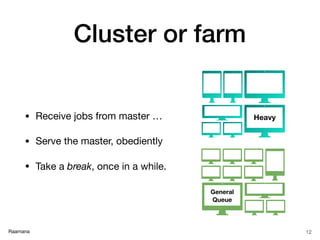
- 12. Raamana Cluster or farm • Receive jobs from master … • Serve the master, obediently • Take a break, once in a while. 12 General Queue Heavy
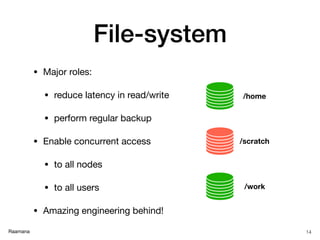
- 14. Raamana File-system • Major roles: • reduce latency in read/write • perform regular backup • Enable concurrent access • to all nodes • to all users • Amazing engineering behind! 14 /home /scratch /work
- 15. Raamana When to use HPC? • When the task is too big (memory) to fit on your own desktop computer! • When you have many small tasks with different parameters! • same task, many different subjects or conditions etc. • same pattern of computing, if not same task. • When your jobs ran too long (months!) • Need > 1 terabyte of disk space • High-speed data access - really high! • No downsides in using it in most cases!! 15 > big node on cluster Cluster
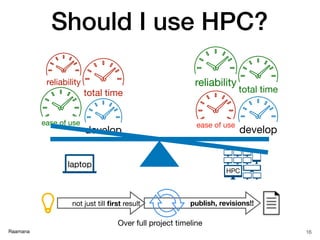
- 16. Raamana total time develop reliability ease of use ease of use develop reliability total time Should I use HPC? 16 HPC laptop Over full project timeline publish, revisions!!not just till first result
- 17. Raamana When to avoid HPC? • When interaction is a big part! • When visualization is a big part! • When you are still “improving” algorithm • Debugging, profiling and optimizing code • BUT, sometimes you need to deploy on big nodes to test them. Then its necessary. • PS: interaction and visualization are both possible - just need more effort to setup. 17 > interact still waiting … > visualize display missing.. error!
- 18. Raamana Types of schedulers 18 SGE Torque/PBS SLURM Variables Easy Hard Easier Features Reasonable Reasonable Many Support Low Low Well-supported Administration Not hard Hard Easy Scalability Medium Low High (millions of jobs) Popularity Okay Not very Highly popular *Raamana’s personal opinion
- 19. Raamana Job Priority 19 Factor Impact First-come first-serve jobs waiting longer get priority Size of resources requested smaller get priority, typically “whole node” jobs are preferred (over partial use) Fair-share groups/users with lesser usage get priority Resource allocation users or groups with prior allocations get higher priority. Must be set-up in advance. *Terms and conditions apply e.g. dependences, availability of resources, type of queue requested etc https://docs.computecanada.ca/wiki/Job_scheduling_policies
- 20. Raamana Resource specification 20 Resource SLURM SGE number of nodes -N [min[-max]] N/A number of CPUs -n [count] -pe [PE] [count] memory (RAM) --mem [size[units]] -l mem_free=[size[units]] total time (wall clock limit) -t [days-hh:mm:ss] OR -t [min] -l h_rt=[seconds] export user environment --export=[ALL | NONE | variables] -V naming a job (important) --job-name=[name] -N [name] output log (stdout) -o [file_name] -o [file_name] error log (stderr) -e [file_name] -e [file_name] join stdout and stderr by default, unless -e specified -j yes queue / partition -p [queue] -q [queue] script directive (inside script) #SBATCH #$ job notification via email --mail-type=[events] -m abe email address for notifications --mail-user=[address] -M [address] Useful glossary: https://www.computecanada.ca/research-portal/accessing-resources/glossary/
- 21. Raamana Node specification 21 Resource SLURM restrict to particular nodes --nodelist=intel[1-5] exclude certain nodes --exclude=amd[6-9] based on features (tags) --constraint=“intel&gpu” to a specific partition or queue --partition intel_gpu based on number of cores/threads --extra-node-info=<sockets[:cores[:threads]]> type of computation --hint=[compute_bound,memory_bound,multithread] contiguous --contiguous CPU frequency --cpu-freq=[Performance,Conservative,PowerSave] Useful glossary: https://www.computecanada.ca/research-portal/accessing-resources/glossary/
- 22. Raamana #!/bin/bash #SBATCH -p general # which partition/queue #SBATCH -N 1 # number of nodes #SBATCH -n 1 # number of cores #SBATCH --mem=4G # total memory #SBATCH -t 0-2:00 # time (D-HH:MM) #SBATCH -o my_output.txt # command to invoke your script python /home/quark/script.py R CMD BATCH stats.R matlab -nodesktop -r matrix.m Making a job from a script 22 > sbatch -n 1 --mem=4G -t 2:00 -o my_output.txt python /home/quark/script.py Recommended
- 23. Raamana Invoking script from shell 23 Language / environment Shell command shell script bash script.sh python python script.py matlab matlab -nodesktop -r script.m R R CMD BATCH script.R
- 24. Raamana Being precise and smaller is wiser! (backfill policy) 24 # CPUs 32 16 8 6 4 2 1 with backfill, you can look ahead, fill unused gaps with jobs waiting in queue. running job! Tail of Queue jobs wait till resources free up! Head of queue jobs to the left get executed without backfill, queue or priority order would be strict. Cluster under-utilized! time *backfill might not always be enabled. Assumes users specified resources! hence, an army of small jobs is better than few big jobs!* otherwise unused CPUs
- 25. Raamana Circle packing: maximize packing density 25 Different sizes intended to show variety of workloads
- 26. Raamana Splitting your workflow 26 • Some tasks are highly parallel • painting different walls • Some tasks have to wait for others • Installing roof, needs all walls built first.
- 27. Raamana Slicing Total Processing 27 Task parallelismData parallelism you can do both, although with varying returns! Note: these are mostly embarrassingly parallel!
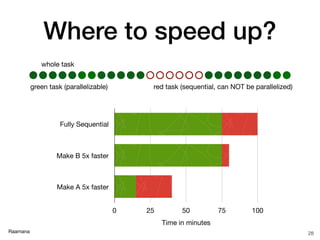
- 28. Raamana Where to speed up? 28 green task (parallelizable) red task (sequential, can NOT be parallelized) Fully Sequential Make B 5x faster Make A 5x faster Time in minutes 0 25 50 75 100 whole task
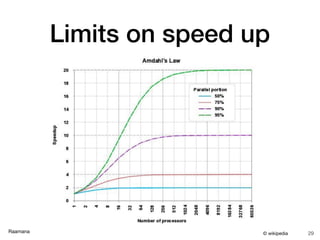
- 29. Raamana Limits on speed up 29© wikipedia
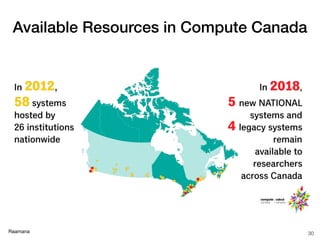
- 30. Raamana 30 Available Resources in Compute Canada
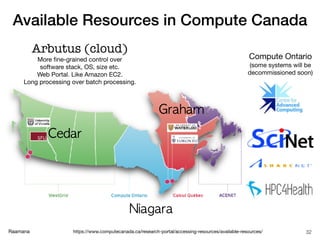
- 32. Raamana Available Resources in Compute Canada https://www.computecanada.ca/research-portal/accessing-resources/available-resources/ 32 Arbutus (cloud) More fine-grained control over software stack, OS, size etc. Web Portal. Like Amazon EC2. Long processing over batch processing. Compute Ontario (some systems will be decommissioned soon)
- 33. Raamana Compute Canada: Available Resources https://www.computecanada.ca/research-portal/accessing-resources/available-resources/ 33 Cedar Niagara (parallel cluster) will soon be operational in 2018 Graham
- 34. Raamana Centre for Advanced Computing (Frontenac) • Brand-new! • Excellent support/admins. • SLURM scheduler, not SGE. • Info: https://cac.queensu.ca • Available software: https://cac.queensu.ca/wiki/index.php/Software:Frontenac 34 Path / Area Quota Backup? Purged? /global/home 1 TB Yes No /global/scratch 5 TB No Yes /global/project 3 TB Yes No /local 1 TB No Yes
- 35. Raamana Rotman Grid (G4) • Convenient, if the data is already stored here at Rotman • 200+ cores, >1.2T RAM, >100T disk space • Fewer users, less competition, sometimes. • Queues from 4CPUs/6GB to 8CPUs/16GB • Other configurations up to 60CPUs/360GB can be easily defined. • Admins are highly reachable. • This will get bigger, talk to Tony and Alain. 35 Path / Area Quota Backup? /home 1 TB Yes /scratch 5 TB No /dataX X TB No gateway or headnode IP: 172.24.4.65
- 36. Raamana Checklist: before you submit • Test and debug your code locally • starting with each of the small parts of the pipeline • whether they are integrated well • reduce redundancy, choosing right output formats etc • sloppy testing and debugging could cost you a lot, later on!! • Test your environment • Run the job locally on the headnode or login node • If not, you can request an interactive job • Do I have enough disk space? • Chalk out job requirements in speed, walltime, RAM, number of jobs etc • to reduce the total processing time (at the level of dataset and experiment) • You many need to select appropriate queue or partition to match your needs and specifications (otherwise you might wait in line forever • Decide on whether to insert checkpoint logic and code • Decide on whether to insert Profiling code (measure its effective speed in different parts of pipeline) • Decide on whether to retain intermediate or scratch outputs? 36
- 37. Raamana Checklist: before you submit • Always try to specify resources! • defaults are not necessarily the best for your need! • job gets scheduled quickly, choosing right queue/specs. • reduces the trial and error to get to the right nodes w/ resources • reduces wastage - don’t take up 8 CPUs and 32Gb to print(“Hello, World!”) • “Know your job” well (profiling!) • Save the job specifications to a file (do not rely on shell history) • Estimate requirements precisely, but be conservative in requesting - add 10-20% • If your matrix needs 2.5GB, specify 4GB for job. • Remember OS on the nodes takes up some RAM - so if the node physically has 32GB, it needs a 2-3GB to run and stay alive. Only jobs requiring less than 30GB will be scheduled to it. Jobs requiring exactly 32GB will be sent to nodes with more than RAM (64 or 128GB) 37
- 38. Raamana Checklist: profile your job • Many tools are available in Linux to “profile” the memory usage and time usage for different parts of your program. • top / htop • free / vmstat • time • Plugins to IDEs for your language • Explicit profiling is typically not necessary! • you know your job during development. • Check the file sizes created during “trial” runs • Keep only what is necessary, after testing! • You don’t need to specify disk space, but need to ensure you won’t create more files exceeding your quota (aggregate over all jobs) • tools: quota, du or df -h • If you are unable to profile on your desktop, • request an interactive job! • Once obtained, acts like your desktop! • Need to think about whether you need a display, when you run jobs! 38
- 39. Raamana • Regularly check on job status • because jobs fail! Many reasons! It sucks. It hurts. No matter how well you tested your code! • Some factors (like network, file system and weather) are not in your control. • Better to accept failures, and reduce the time to resubmit them. • Hence checkpointing is important! • so you reuse what was finished already before failure! • You may need to write scripts to get an accurate estimate of status of processing! • as your pipeline can be complicated • rely on files written to disk, than text output in a log • unless you designed it that way 39 Checklist: during execution
- 40. Raamana • Check various things!! • Check file sizes (file being there doesn’t mean it has data) • Visualize them (data present doesn’t mean its accurate) • Sweep across all jobs! • Check disk usage. • Track usage: • memory, walltime, disk I/O etc. • to optimize job specs next time • as it’s never a one time thing! • Again, scripts can help • automating this process • mad shell skills also help. 40 Checklist: after execution
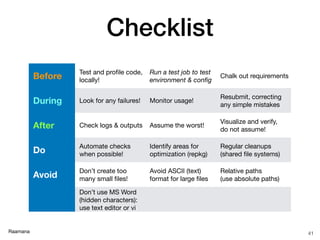
- 41. Raamana Checklist 41 Before Test and profile code, locally! Run a test job to test environment & config Chalk out requirements During Look for any failures! Monitor usage! Resubmit, correcting any simple mistakes After Check logs & outputs Assume the worst! Visualize and verify, do not assume! Do Automate checks when possible! Identify areas for optimization (repkg) Regular cleanups (shared file systems) Avoid Don’t create too many small files! Avoid ASCII (text) format for large files Relative paths (use absolute paths) Don’t use MS Word (hidden characters): use text editor or vi
- 42. Raamana Progress is not always linear! 42 sometimes, no-one else can help you, or has time.
- 43. Raamana Data transfer tools 43 Task Recommended Alternatives download wget URL browser and scp synchronize rsync -av /src server:/dest scp (batch, simplest) sftp (interactive) bbcp (parallel; large sizes) reduce size tar -cvf (create / zip) tar -xvf (extract/unzip) zip unzip software FileZilla(desktop to cluster) Globus (between clusters) WinSCP (windows) FireFTP (cross-platform) Transmit, Fugu (Mac) https://docs.computecanada.ca/wiki/Globus When in doubt, don’t delete data. When in doubt, email the admins!
- 44. Raamana Data management plan! • Calculate size of data you’ll produce from test runs. • What do you need to “keep”, and how long? • When is data “final” and needs to be backed up? • What is scratch and deletable, and what is not? • Is the “intermediate” data easy & quick to regenerate? • If so, should you even store it? 44
- 45. Raamana Should I build a pipeline? 45 • Can few parts of my project be automated? Together? • Do I repeat this processing/analysis? More than twice? • Even if they are repeated in a different manner, can I capture the variations in logic? • Are there delays due to human involvement? • Is it difficult to redo this on a different dataset or by others? • Are there concerns of reproducibility in my analysis? Yes No Yes No Yes No Yes No Yes No Yes No My thesis: “Most things can be automated!” Yes 4/6?
- 46. Raamana Building pipelines • We usually need to stitch together a diverse array of tools (AFNI, FSL, Python, R etc) to achieve a larger goal (build a pipeline) • They are often written in different programming languages (Matlab, C++, Python, R etc) • Mostly compiled, and no APIs • To reduce your pain, you can use bash or Python to develop a pipeline. • If it’s neuroimaging-specific, check nipy also • So, learning a bit of bash/Python really helps! • be warned, bash is not super easy, but very helpful for relatively straightforward pipelines! 46 no heavy logic? Use: When in doubt, use:
- 47. Raamana HPC Skills • Learning Linux goes a long way. • Most HPC clusters are in Linux! • It is reliable and free. • Great to build pipelines • Understanding of scheduling • Command-line skills • batch processing is king!! • human interaction is slow! • Scripting in bash/python • to stitch together routine or repetitive tasks into a pipeline! 47
- 48. Raamana Thesis/papers over pipeline! • Remember, • you want to do this to solve your own problem(s), and save time now! • and tomorrow, as reuse it! • as well as others later on. • However, • no immediate reward • not in academia! • not for pure programming. 48 • If you enjoy it, • no reason not to improve the world!
- 49. Raamana Submit your questions now! 49 I will batch process them in queue.
- 50. Raamana Any questions before we move on to a hands-on demo? 50