ML | Data Preprocessing in Python
Last Updated : 17 Jan, 2025
Data preprocessing is a important step in the data science transforming raw data into a clean structured format for analysis. It involves tasks like handling missing values, normalizing data and encoding variables. Mastering preprocessing in Python ensures reliable insights for accurate predictions and effective decision-making. Pre-processing refers to the transformations applied to data before feeding it to the algorithm.
Data Preprocessing
Steps in Data Preprocessing
Step 1: Import the necessary libraries
Python# importing librariesimportpandasaspdimportscipyimportnumpyasnpfromsklearn.preprocessingimportMinMaxScalerimportseabornassnsimportmatplotlib.pyplotasplt
Step 2: Load the dataset
You can download dataset from here.
Python# Load the datasetdf=pd.read_csv('Geeksforgeeks/Data/diabetes.csv')print(df.head())Output:
Pregnancies Glucose BloodPressure SkinThickness Insulin BMI 0 6 148 72 35 0 33.6 \ 1 1 85 66 29 0 26.6 2 8 183 64 0 0 23.3 3 1 89 66 23 94 28.1 4 0 137 40 35 168 43.1 DiabetesPedigreeFunction Age Outcome 0 0.627 50 1 1 0.351 31 0 2 0.672 32 1 3 0.167 21 0 4 2.288 33 1
1. Check the data info
PythonOutput:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 768 entries, 0 to 767 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Pregnancies 768 non-null int64 1 Glucose 768 non-null int64 2 BloodPressure 768 non-null int64 3 SkinThickness 768 non-null int64 4 Insulin 768 non-null int64 5 BMI 768 non-null float64 6 DiabetesPedigreeFunction 768 non-null float64 7 Age 768 non-null int64 8 Outcome 768 non-null int64 dtypes: float64(2), int64(7) memory usage: 54.1 KB
As we can see from the above info that the our dataset has 9 columns and each columns has 768 values. There is no Null values in the dataset.
We can also check the null values using df.isnull()
PythonOutput:
Pregnancies 0 Glucose 0 BloodPressure 0 SkinThickness 0 Insulin 0 BMI 0 DiabetesPedigreeFunction 0 Age 0 Outcome 0 dtype: int64
Step 2: Statistical Analysis
In statistical analysis we use df.describe() which will give a descriptive overview of the dataset.
PythonOutput:
.png)
Data summary
The above table shows the count, mean, standard deviation, min, 25%, 50%, 75% and max values for each column. When we carefully observe the table we will find that Insulin, Pregnancies, BMI, BloodPressure columns has outliers.
Let’s plot the boxplot for each column for easy understanding.
Step 3: Check the outliers
Python# Box Plotsfig,axs=plt.subplots(9,1,dpi=95,figsize=(7,17))i=0forcolindf.columns:axs[i].boxplot(df[col],vert=False)axs[i].set_ylabel(col)i+=1plt.show()
Output:
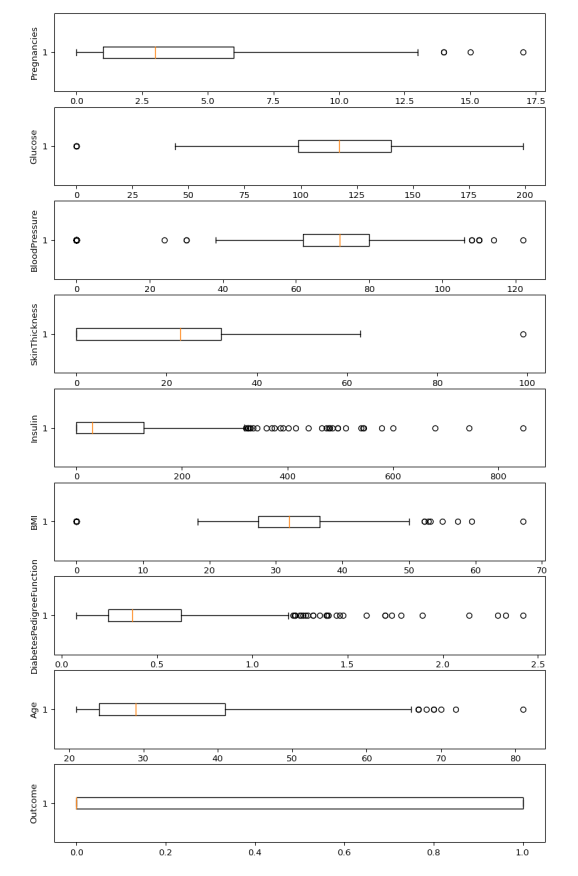
Boxplots
from the above boxplot we can clearly see that every column has some amounts of outliers.
Step 4: Drop the outliers
Python# Identify the quartilesq1,q3=np.percentile(df['Insulin'],[25,75])# Calculate the interquartile rangeiqr=q3-q1# Calculate the lower and upper boundslower_bound=q1-(1.5*iqr)upper_bound=q3+(1.5*iqr)# Drop the outliersclean_data=df[(df['Insulin']>=lower_bound)&(df['Insulin']<=upper_bound)]# Identify the quartilesq1,q3=np.percentile(clean_data['Pregnancies'],[25,75])# Calculate the interquartile rangeiqr=q3-q1# Calculate the lower and upper boundslower_bound=q1-(1.5*iqr)upper_bound=q3+(1.5*iqr)# Drop the outliersclean_data=clean_data[(clean_data['Pregnancies']>=lower_bound)&(clean_data['Pregnancies']<=upper_bound)]# Identify the quartilesq1,q3=np.percentile(clean_data['Age'],[25,75])# Calculate the interquartile rangeiqr=q3-q1# Calculate the lower and upper boundslower_bound=q1-(1.5*iqr)upper_bound=q3+(1.5*iqr)# Drop the outliersclean_data=clean_data[(clean_data['Age']>=lower_bound)&(clean_data['Age']<=upper_bound)]# Identify the quartilesq1,q3=np.percentile(clean_data['Glucose'],[25,75])# Calculate the interquartile rangeiqr=q3-q1# Calculate the lower and upper boundslower_bound=q1-(1.5*iqr)upper_bound=q3+(1.5*iqr)# Drop the outliersclean_data=clean_data[(clean_data['Glucose']>=lower_bound)&(clean_data['Glucose']<=upper_bound)]# Identify the quartilesq1,q3=np.percentile(clean_data['BloodPressure'],[25,75])# Calculate the interquartile rangeiqr=q3-q1# Calculate the lower and upper boundslower_bound=q1-(0.75*iqr)upper_bound=q3+(0.75*iqr)# Drop the outliersclean_data=clean_data[(clean_data['BloodPressure']>=lower_bound)&(clean_data['BloodPressure']<=upper_bound)]# Identify the quartilesq1,q3=np.percentile(clean_data['BMI'],[25,75])# Calculate the interquartile rangeiqr=q3-q1# Calculate the lower and upper boundslower_bound=q1-(1.5*iqr)upper_bound=q3+(1.5*iqr)# Drop the outliersclean_data=clean_data[(clean_data['BMI']>=lower_bound)&(clean_data['BMI']<=upper_bound)]# Identify the quartilesq1,q3=np.percentile(clean_data['DiabetesPedigreeFunction'],[25,75])# Calculate the interquartile rangeiqr=q3-q1# Calculate the lower and upper boundslower_bound=q1-(1.5*iqr)upper_bound=q3+(1.5*iqr)# Drop the outliersclean_data=clean_data[(clean_data['DiabetesPedigreeFunction']>=lower_bound)&(clean_data['DiabetesPedigreeFunction']<=upper_bound)]
Step 5: Correlation
Python#correlationcorr=df.corr()plt.figure(dpi=130)sns.heatmap(df.corr(),annot=True,fmt='.2f')plt.show()
Output:
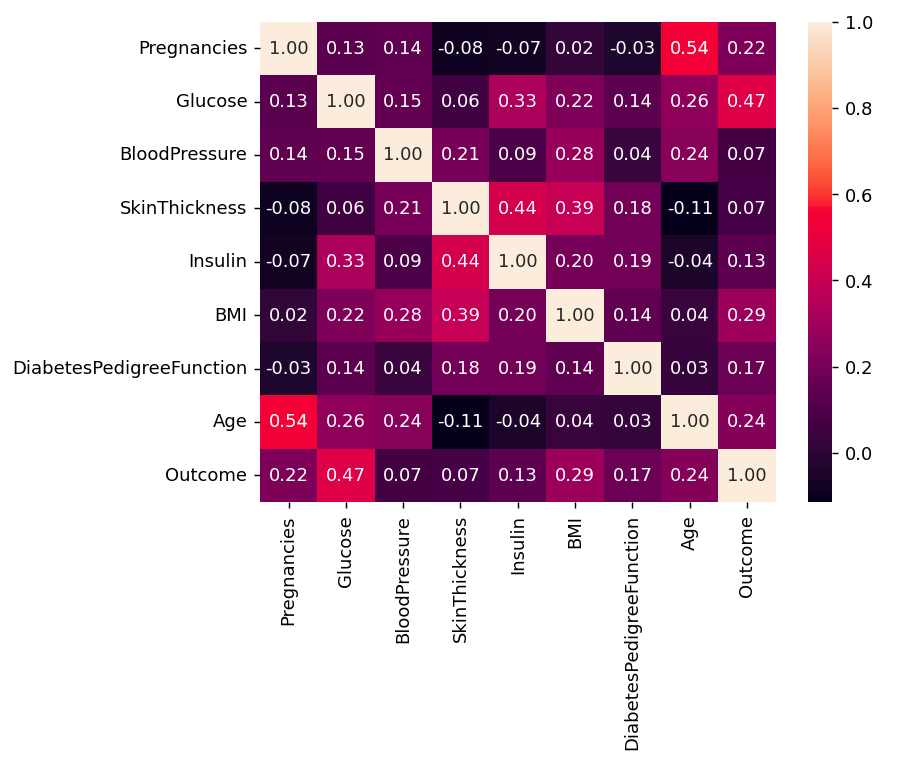
Correlation
We can also compare by single columns in descending order
Pythoncorr['Outcome'].sort_values(ascending=False)
Output:
Outcome 1.000000 Glucose 0.466581 BMI 0.292695 Age 0.238356 Pregnancies 0.221898 DiabetesPedigreeFunction 0.173844 Insulin 0.130548 SkinThickness 0.074752 BloodPressure 0.0
Step 6: Check Outcomes Proportionality
Pythonplt.pie(df.Outcome.value_counts(),labels=['Diabetes','Not Diabetes'],autopct='%.f',shadow=True)plt.title('Outcome Proportionality')plt.show()Output:
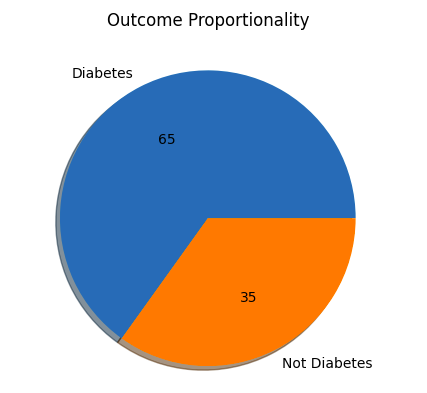
Outcome Proportionality
Step 7: Separate independent features and Target Variables
Python# separate array into input and output componentsX=df.drop(columns=['Outcome'])Y=df.Outcome
Step 7: Normalization or Standardization
Normalization
- Normalization works well when the features have different scales and the algorithm being used is sensitive to the scale of the features, such as k-nearest neighbors or neural networks.
- Rescale your data using scikit-learn using the MinMaxScaler.
- MinMaxScaler scales the data so that each feature is in the range [0, 1].
Python# initialising the MinMaxScalerscaler=MinMaxScaler(feature_range=(0,1))# learning the statistical parameters for each of the data and transformingrescaledX=scaler.fit_transform(X)rescaledX[:5]
Output:
array([[0.353, 0.744, 0.59 , 0.354, 0. , 0.501, 0.234, 0.483], [0.059, 0.427, 0.541, 0.293, 0. , 0.396, 0.117, 0.167], [0.471, 0.92 , 0.525, 0. , 0. , 0.347, 0.254, 0.183], [0.059, 0.447, 0.541, 0.232, 0.111, 0.419, 0.038, 0. ], [0. , 0.688, 0.328, 0.354, 0.199, 0.642, 0.944, 0.2 ]])
Standardization
- Standardization is a useful technique to transform attributes with a Gaussian distribution and differing means and standard deviations to a standard Gaussian distribution with a mean of 0 and a standard deviation of 1.
- We can standardize data using scikit-learn with the StandardScaler class.
- It works well when the features have a normal distribution or when the algorithm being used is not sensitive to the scale of the features
Pythonfromsklearn.preprocessingimportStandardScalerscaler=StandardScaler().fit(X)rescaledX=scaler.transform(X)rescaledX[:5]
Output:
array([[ 0.64 , 0.848, 0.15 , 0.907, -0.693, 0.204, 0.468, 1.426], [-0.845, -1.123, -0.161, 0.531, -0.693, -0.684, -0.365, -0.191], [ 1.234, 1.944, -0.264, -1.288, -0.693, -1.103, 0.604, -0.106], [-0.845, -0.998, -0.161, 0.155, 0.123, -0.494, -0.921, -1.042], [-1.142, 0.504, -1.505, 0.907, 0.766, 1.41 , 5.485]
In conclusion data preprocessing is an important step to make raw data clean for analysis. Using Python we can handle missing values, organize data and prepare it for accurate results. This ensures our model is reliable and helps us uncover valuable insights from data.
Similar Reads
Data Analysis with Python
In this article, we will discuss how to do data analysis with Python. We will discuss all sorts of data analysis i.e. analyzing numerical data with NumPy, Tabular data with Pandas, data visualization Matplotlib, and Exploratory data analysis. Data Analysis With Python Data Analysis is the technique
15+ min read
Introduction to Data Analysis
Data Analysis Libraries
Pandas Tutorial
Pandas is an open-source software library designed for data manipulation and analysis. It provides data structures like series and DataFrames to easily clean, transform and analyze large datasets and integrates with other Python libraries, such as NumPy and Matplotlib. It offers functions for data t
7 min read
NumPy Tutorial - Python Library
NumPy is a powerful library for numerical computing in Python. It provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays. NumPy’s array objects are more memory-efficient and perform better than Python lists, whi
7 min read
Data Analysis with SciPy
Scipy is a Python library useful for solving many mathematical equations and algorithms. It is designed on the top of Numpy library that gives more extension of finding scientific mathematical formulae like Matrix Rank, Inverse, polynomial equations, LU Decomposition, etc. Using its high-level funct
6 min read
Introduction to TensorFlow
TensorFlow is an open-source framework for machine learning (ML) and artificial intelligence (AI) that was developed by Google Brain. It was designed to facilitate the development of machine learning models, particularly deep learning models, by providing tools to easily build, train, and deploy the
6 min read
Data Visulization Libraries
Matplotlib Tutorial
Matplotlib is an open-source visualization library for the Python programming language, widely used for creating static, animated and interactive plots. It provides an object-oriented API for embedding plots into applications using general-purpose GUI toolkits like Tkinter, Qt, GTK and wxPython. It
5 min read
Python Seaborn Tutorial
Seaborn is a library mostly used for statistical plotting in Python. It is built on top of Matplotlib and provides beautiful default styles and color palettes to make statistical plots more attractive. In this tutorial, we will learn about Python Seaborn from basics to advance using a huge dataset o
15+ min read
Plotly tutorial
Plotly library in Python is an open-source library that can be used for data visualization and understanding data simply and easily. Plotly supports various types of plots like line charts, scatter plots, histograms, box plots, etc. So you all must be wondering why Plotly is over other visualization
15+ min read
Introduction to Bokeh in Python
Bokeh is a Python interactive data visualization. Unlike Matplotlib and Seaborn, Bokeh renders its plots using HTML and JavaScript. It targets modern web browsers for presentation providing elegant, concise construction of novel graphics with high-performance interactivity. Features of Bokeh: Some o
1 min read
Exploratory Data Analysis (EDA)
Univariate, Bivariate and Multivariate data and its analysis
In this article,we will be discussing univariate, bivariate, and multivariate data and their analysis. Univariate data: Univariate data refers to a type of data in which each observation or data point corresponds to a single variable. In other words, it involves the measurement or observation of a s
5 min read
Measures of Central Tendency in Statistics
Central Tendencies in Statistics are the numerical values that are used to represent mid-value or central value a large collection of numerical data. These obtained numerical values are called central or average values in Statistics. A central or average value of any statistical data or series is th
10 min read
Measures of Spread - Range, Variance, and Standard Deviation
Collecting the data and representing it in form of tables, graphs, and other distributions is essential for us. But, it is also essential that we get a fair idea about how the data is distributed, how scattered it is, and what is the mean of the data. The measures of the mean are not enough to descr
9 min read
Interquartile Range and Quartile Deviation using NumPy and SciPy
In statistical analysis, understanding the spread or variability of a dataset is crucial for gaining insights into its distribution and characteristics. Two common measures used for quantifying this variability are the interquartile range (IQR) and quartile deviation. Quartiles Quartiles are a kind
5 min read
Anova Formula
ANOVA Test, or Analysis of Variance, is a statistical method used to test the differences between the means of two or more groups. Developed by Ronald Fisher in the early 20th century, ANOVA helps determine whether there are any statistically significant differences between the means of three or mor
7 min read
Skewness of Statistical Data
Skewness is a measure of the asymmetry of the probability distribution of a real-valued random variable about its mean. In simpler terms, it indicates whether the data is concentrated more on one side of the mean compared to the other side. Why is skewness important?Understanding the skewness of dat
5 min read
How to Calculate Skewness and Kurtosis in Python?
Skewness is a statistical term and it is a way to estimate or measure the shape of a distribution. It is an important statistical methodology that is used to estimate the asymmetrical behavior rather than computing frequency distribution. Skewness can be two types: Symmetrical: A distribution can be
3 min read
Difference Between Skewness and Kurtosis
What is Skewness? Skewness is an important statistical technique that helps to determine the asymmetrical behavior of the frequency distribution, or more precisely, the lack of symmetry of tails both left and right of the frequency curve. A distribution or dataset is symmetric if it looks the same t
4 min read
Histogram | Meaning, Example, Types and Steps to Draw
What is Histogram?A histogram is a graphical representation of the frequency distribution of continuous series using rectangles. The x-axis of the graph represents the class interval, and the y-axis shows the various frequencies corresponding to different class intervals. A histogram is a two-dimens
5 min read
Interpretations of Histogram
Histograms helps visualizing and comprehending the data distribution. The article aims to provide comprehensive overview of histogram and its interpretation. What is Histogram?Histograms are graphical representations of data distributions. They consist of bars, each representing the frequency or cou
7 min read
Box Plot
Box Plot is a graphical method to visualize data distribution for gaining insights and making informed decisions. Box plot is a type of chart that depicts a group of numerical data through their quartiles. In this article, we are going to discuss components of a box plot, how to create a box plot, u
7 min read
Quantile Quantile plots
The quantile-quantile( q-q plot) plot is a graphical method for determining if a dataset follows a certain probability distribution or whether two samples of data came from the same population or not. Q-Q plots are particularly useful for assessing whether a dataset is normally distributed or if it
8 min read
What is Univariate, Bivariate & Multivariate Analysis in Data Visualisation?
Data Visualisation is a graphical representation of information and data. By using different visual elements such as charts, graphs, and maps data visualization tools provide us with an accessible way to find and understand hidden trends and patterns in data. In this article, we are going to see abo
3 min read
Using pandas crosstab to create a bar plot
In this article, we will discuss how to create a bar plot by using pandas crosstab in Python. First Lets us know more about the crosstab, It is a simple cross-tabulation of two or more variables. What is cross-tabulation? It is a simple cross-tabulation that help us to understand the relationship be
3 min read
Exploring Correlation in Python
This article aims to give a better understanding of a very important technique of multivariate exploration. A correlation Matrix is basically a covariance matrix. Also known as the auto-covariance matrix, dispersion matrix, variance matrix, or variance-covariance matrix. It is a matrix in which the
4 min read
Covariance and Correlation
Covariance and correlation are the two key concepts in Statistics that help us analyze the relationship between two variables. Covariance measures how two variables change together, indicating whether they move in the same or opposite directions. In this article, we will learn about the differences
5 min read
Factor Analysis | Data Analysis
Factor analysis is a statistical method used to analyze the relationships among a set of observed variables by explaining the correlations or covariances between them in terms of a smaller number of unobserved variables called factors. Table of Content What is Factor Analysis?What does Factor mean i
13 min read
Data Mining - Cluster Analysis
Data mining is the process of finding patterns, relationships and trends to gain useful insights from large datasets. It includes techniques like classification, regression, association rule mining and clustering. In this article, we will learn about clustering analysis in data mining. Understanding
6 min read
MANOVA Test in R Programming
Multivariate analysis of variance (MANOVA) is simply an ANOVA (Analysis of variance) with several dependent variables. It is a continuation of the ANOVA. In an ANOVA, we test for statistical differences on one continuous dependent variable by an independent grouping variable. The MANOVA continues th
3 min read
MANOVA Test in R Programming
Multivariate analysis of variance (MANOVA) is simply an ANOVA (Analysis of variance) with several dependent variables. It is a continuation of the ANOVA. In an ANOVA, we test for statistical differences on one continuous dependent variable by an independent grouping variable. The MANOVA continues th
3 min read
Python - Central Limit Theorem
Central Limit Theorem (CLT) is a foundational principle in statistics, and implementing it using Python can significantly enhance data analysis capabilities. Statistics is an important part of data science projects. We use statistical tools whenever we want to make any inference about the population
7 min read
Probability Distribution Function
Probability Distribution refers to the function that gives the probability of all possible values of a random variable.It shows how the probabilities are assigned to the different possible values of the random variable.Common types of probability distributions Include: Binomial Distribution.Bernoull
9 min read
Probability Density Estimation & Maximum Likelihood Estimation
Probability density and maximum likelihood estimation (MLE) are key ideas in statistics that help us make sense of data. Probability Density Function (PDF) tells us how likely different outcomes are for a continuous variable, while Maximum Likelihood Estimation helps us find the best-fitting model f
8 min read
Exponential Distribution in R Programming - dexp(), pexp(), qexp(), and rexp() Functions
The exponential distribution in R Language is the probability distribution of the time between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate. It is a particular case of the gamma distribution. In R Programming Langu
2 min read
Mathematics | Probability Distributions Set 4 (Binomial Distribution)
The previous articles talked about some of the Continuous Probability Distributions. This article covers one of the distributions which are not continuous but discrete, namely the Binomial Distribution. Introduction - To understand the Binomial distribution, we must first understand what a Bernoulli
5 min read
Poisson Distribution | Definition, Formula, Table and Examples
The Poisson distribution is a discrete probability distribution that calculates the likelihood of a certain number of events happening in a fixed time or space, assuming the events occur independently and at a constant rate. It is characterized by a single parameter, λ (lambda), which represents the
11 min read
P-Value: Comprehensive Guide to Understand, Apply, and Interpret
A p-value is a statistical metric used to assess a hypothesis by comparing it with observed data. This article delves into the concept of p-value, its calculation, interpretation, and significance. It also explores the factors that influence p-value and highlights its limitations. Table of Content W
12 min read
Z-Score in Statistics | Definition, Formula, Calculation and Uses
Z-Score in statistics is a measurement of how many standard deviations away a data point is from the mean of a distribution. A z-score of 0 indicates that the data point's score is the same as the mean score. A positive z-score indicates that the data point is above average, while a negative z-score
15+ min read
How to Calculate Point Estimates in R?
Point estimation is a technique used to find the estimate or approximate value of population parameters from a given data sample of the population. The point estimate is calculated for the following two measuring parameters: Measuring parameterPopulation ParameterPoint EstimateProportionπp Meanμx̄ T
3 min read
Confidence Interval
Confidence Interval (CI) is a range of values that estimates where the true population value is likely to fall. Instead of just saying The average height of students is 165 cm a confidence interval allow us to say We are 95% confident that the true average height is between 160 cm and 170 cm. Before
9 min read
Chi-square test in Machine Learning
Chi-Square test helps us determine if there is a significant relationship between two categorical variables and the target variable. It is a non-parametric statistical test meaning it doesn’t follow normal distribution. It checks whether there’s a significant difference between expected and observed
9 min read
Understanding Hypothesis Testing
Hypothesis method compares two opposite statements about a population and uses sample data to decide which one is more likely to be correct.To test this assumption we first take a sample from the population and analyze it and use the results of the analysis to decide if the claim is valid or not. Su
14 min read
Time Series Data Analysis
Data Mining - Time-Series, Symbolic and Biological Sequences Data
Data mining refers to extracting or mining knowledge from large amounts of data. In other words, Data mining is the science, art, and technology of discovering large and complex bodies of data in order to discover useful patterns. Theoreticians and practitioners are continually seeking improved tech
3 min read
Basic DateTime Operations in Python
Python has an in-built module named DateTime to deal with dates and times in numerous ways. In this article, we are going to see basic DateTime operations in Python. There are six main object classes with their respective components in the datetime module mentioned below: datetime.datedatetime.timed
12 min read
Time Series Analysis & Visualization in Python
Every dataset has distinct qualities that function as essential aspects in the field of data analytics, providing insightful information about the underlying data. Time series data is one kind of dataset that is especially important. This article delves into the complexities of time series datasets,
11 min read
How to deal with missing values in a Timeseries in Python?
It is common to come across missing values when working with real-world data. Time series data is different from traditional machine learning datasets because it is collected under varying conditions over time. As a result, different mechanisms can be responsible for missing records at different tim
10 min read
How to calculate MOVING AVERAGE in a Pandas DataFrame?
Calculating the moving average in a Pandas DataFrame is used for smoothing time series data and identifying trends. The moving average, also known as the rolling mean, helps reduce noise and highlight significant patterns by averaging data points over a specific window. In Pandas, this can be achiev
7 min read
What is a trend in time series?
Time series data is a sequence of data points that measure some variable over ordered period of time. It is the fastest-growing category of databases as it is widely used in a variety of industries to understand and forecast data patterns. So while preparing this time series data for modeling it's i
3 min read
How to Perform an Augmented Dickey-Fuller Test in R
Augmented Dickey-Fuller Test: It is a common test in statistics and is used to check whether a given time series is at rest. A given time series can be called stationary or at rest if it doesn't have any trend and depicts a constant variance over time and follows autocorrelation structure over a per
3 min read
AutoCorrelation
Autocorrelation is a fundamental concept in time series analysis. Autocorrelation is a statistical concept that assesses the degree of correlation between the values of variable at different time points. The article aims to discuss the fundamentals and working of Autocorrelation. Table of Content Wh
10 min read
Case Studies and Projects