Use Gemini 2.0 to speed up document extraction and lower costs
Meenu Bondili
Field Solutions Developer, Generative AI
Jonathan Chen
Gen AI Field Solutions Architects Manager
A few weeks ago, Google DeepMind released Gemini 2.0 for everyone, including Gemini 2.0 Flash, Gemini 2.0 Flash-Lite, and Gemini 2.0 Pro (Experimental). All models support up to at least 1 million input tokens, which makes it easier to do a lot of things – from image generation to creative writing. It’s also changed how we convert documents into structured data. Manual document processing is a slow and expensive problem, but Gemini 2.0 changed everything when it comes to chunking pdfs for RAG systems, and can even transform pdfs into insights.
Today, we'll take a deep dive into a multi-step approach using generative AI where you can use Gemini 2.0 to improve your document extraction by combining language models (LLMs) with structured, externalized rules.
A multi-step approach to document extraction, made easy
A multi-step architecture, as opposed to relying on a single, monolithic prompt, offers significant advantages for robust extraction. This approach begins with modular extraction, where initial tasks are broken down into smaller, more focused prompts targeting specific content locations within a document. This modularity not only enhances accuracy but also reduces the cognitive load on the LLM.
Another benefit of a multi-step approach is externalized rule management. By managing post-processing rules externally, for instance, using Google Sheets or a BigQuery table, we gain the benefits of easy CRUD (Create, Read, Update, Delete) operations, improving both maintainability and version control of the rules. This decoupling also separates the logic of extraction from the logic of processing, allowing for independent modification and optimization of each.
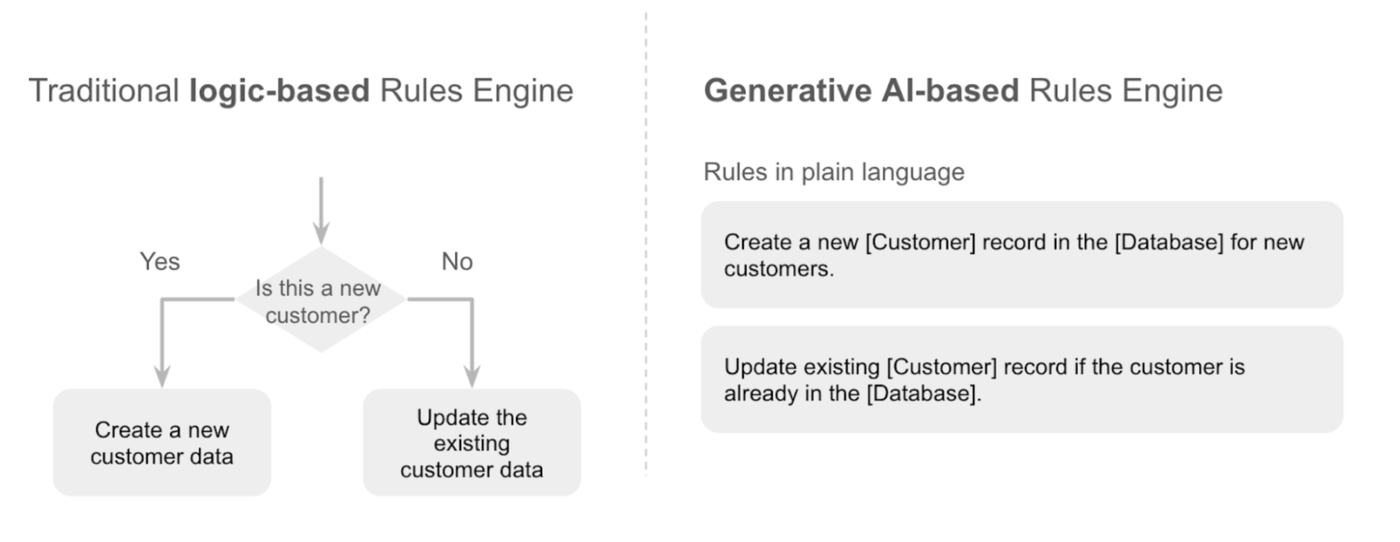
Ultimately, this hybrid approach combines the strengths of LLM-powered extraction with a structured rules engine. LLMs handle the complexities of understanding and extracting information from unstructured data, while the rules engine provides a transparent and manageable system for enforcing business logic and decision-making. The following steps outline a practical implementation.
Step 1: Extraction
Let's test a sample prompt with a configurable set of rules. This hands-on example will demonstrate how easily you can define and apply business logic to extracted data, all powered by the Gemini and Vertex AI.
First, we extract data from a document. Let’s use Google’s 2023 Environment Report as the source document. We use Gemini with the initial prompt to extract data. This is not a known schema, but a prompt we’ve created for the purposes of this story. To create specific response schemas, use controlled generation with Gemini.
The JSON output below, which we'll assign to the variable `extracted_data`, represents the results of the initial data extraction by Gemini. This structured data is now ready for the next critical phase: applying our predefined business rules.
Step 2: Feed the extracted data into a rules engine
Next, we'll feed this `extracted_data` into a rules engine, which, in our implementation, is another call to Gemini, acting as a powerful and flexible rules processor. Along with the extracted data, we'll provide a set of validation rules defined in the `analysis_rules` variable. This engine, powered by Gemini, will systematically check the extracted data for accuracy, consistency, and adherence to our predefined criteria. Below is the prompt we provide to Gemini to accomplish this, along with the rules themselves.
`analysis_rules` is a JSON object that contains the business rules we want to apply to the extracted receipt data. Each rule defines a specific condition to check, an action to take if the condition is met, and an optional alert message if a violation occurs. The power of this approach lies in the flexibility of these rules; you can easily add, modify, or remove them without altering the core extraction process. The beauty of using Gemini is that the rules can be written in human-readable language and can be maintained by non-coders.
Step 3: Integrate your insights
Finally – and crucially – integrate the alerts and insights generated by the rules engine into existing data pipelines and workflows. This is where the real value of this multi-step process is unlocked. For our example, we can build robust APIs and systems using Google Cloud tools to automate downstream actions triggered by the rule-based analysis. Some examples of downstream tasks are:
Automated task creation: Trigger Cloud Functions to create tasks in project management systems, assigning data verification to the appropriate teams.
Data quality pipelines: Integrate with Dataflow to flag potential data inconsistencies in BigQuery tables, triggering validation workflows.
Vertex AI integration: Leverage Vertex AI Model Registry for tracking data lineage and model performance related to extracted metrics and corrections made.
Dashboard integration Use Looker, Google Sheets, or Data Studio to display alerts
Human in the loop trigger: Build a trigger system for the Human in the loop, using Cloud Tasks, to show which extractions to focus on and double check.
Make document extraction easier today
This hands-on approach provides a solid foundation for building robust, rule-driven document extraction pipelines. To get started, explore these resources:
Gemini for document understanding: For a comprehensive, one-stop solution to your document processing needs, check out Gemini for document understanding. It simplifies many common extraction challenges.
Few-shot prompting: Begin your Gemini journey withfew-shot prompting. This powerful technique can significantly improve the quality of your extractions with minimal effort, providing examples within the prompt itself.
Fine-tuning Gemini models: When you need highly specialized, domain-specific extraction results, consider fine-tuning Gemini models. This allows you to tailor the model's performance to your exact requirements.



