| title | category | tag | |
|---|---|---|---|
LinkedList 源码分析 | Java |
|
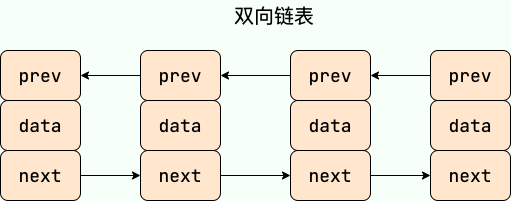
LinkedList 是一个基于双向链表实现的集合类,经常被拿来和 ArrayList 做比较。关于 LinkedList 和ArrayList的详细对比,我们 Java 集合常见面试题总结(上)有详细介绍到。
不过,我们在项目中一般是不会使用到 LinkedList 的,需要用到 LinkedList 的场景几乎都可以使用 ArrayList 来代替,并且,性能通常会更好!就连 LinkedList 的作者约书亚 · 布洛克(Josh Bloch)自己都说从来不会使用 LinkedList 。
另外,不要下意识地认为 LinkedList 作为链表就最适合元素增删的场景。我在上面也说了,LinkedList 仅仅在头尾插入或者删除元素的时候时间复杂度近似 O(1),其他情况增删元素的平均时间复杂度都是 O(n) 。
- 头部插入/删除:只需要修改头结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
- 尾部插入/删除:只需要修改尾结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
- 指定位置插入/删除:需要先移动到指定位置,再修改指定节点的指针完成插入/删除,不过由于有头尾指针,可以从较近的指针出发,因此需要遍历平均 n/4 个元素,时间复杂度为 O(n)。
RandomAccess 是一个标记接口,用来表明实现该接口的类支持随机访问(即可以通过索引快速访问元素)。由于 LinkedList 底层数据结构是链表,内存地址不连续,只能通过指针来定位,不支持随机快速访问,所以不能实现 RandomAccess 接口。
这里以 JDK1.8 为例,分析一下 LinkedList 的底层核心源码。
LinkedList 的类定义如下:
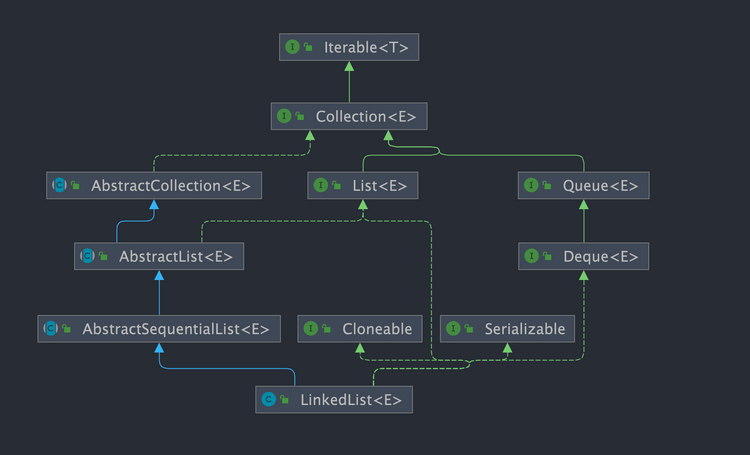
publicclassLinkedList<E> extendsAbstractSequentialList<E> implementsList<E>, Deque<E>, Cloneable, java.io.Serializable { //... }LinkedList 继承了 AbstractSequentialList ,而 AbstractSequentialList 又继承于 AbstractList 。
阅读过 ArrayList 的源码我们就知道,ArrayList 同样继承了 AbstractList , 所以 LinkedList 会有大部分方法和 ArrayList 相似。
LinkedList 实现了以下接口:
List: 表明它是一个列表,支持添加、删除、查找等操作,并且可以通过下标进行访问。Deque:继承自Queue接口,具有双端队列的特性,支持从两端插入和删除元素,方便实现栈和队列等数据结构。需要注意,Deque的发音为 "deck" [dɛk],这个大部分人都会读错。Cloneable:表明它具有拷贝能力,可以进行深拷贝或浅拷贝操作。Serializable: 表明它可以进行序列化操作,也就是可以将对象转换为字节流进行持久化存储或网络传输,非常方便。
LinkedList 中的元素是通过 Node 定义的:
privatestaticclassNode<E> { Eitem;// 节点值Node<E> next; // 指向的下一个节点(后继节点)Node<E> prev; // 指向的前一个节点(前驱结点)// 初始化参数顺序分别是:前驱结点、本身节点值、后继节点Node(Node<E> prev, Eelement, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }LinkedList 中有一个无参构造函数和一个有参构造函数。
// 创建一个空的链表对象publicLinkedList() { } // 接收一个集合类型作为参数,会创建一个与传入集合相同元素的链表对象publicLinkedList(Collection<? extendsE> c) { this(); addAll(c); }LinkedList 除了实现了 List 接口相关方法,还实现了 Deque 接口的很多方法,所以我们有很多种方式插入元素。
我们这里以 List 接口中相关的插入方法为例进行源码讲解,对应的是add() 方法。
add() 方法有两个版本:
add(E e):用于在LinkedList的尾部插入元素,即将新元素作为链表的最后一个元素,时间复杂度为 O(1)。add(int index, E element):用于在指定位置插入元素。这种插入方式需要先移动到指定位置,再修改指定节点的指针完成插入/删除,因此需要移动平均 n/4 个元素,时间复杂度为 O(n)。
// 在链表尾部插入元素publicbooleanadd(Ee) { linkLast(e); returntrue; } // 在链表指定位置插入元素publicvoidadd(intindex, Eelement) { // 下标越界检查checkPositionIndex(index); // 判断 index 是不是链表尾部位置if (index == size) // 如果是就直接调用 linkLast 方法将元素节点插入链表尾部即可linkLast(element); else// 如果不是则调用 linkBefore 方法将其插入指定元素之前linkBefore(element, node(index)); } // 将元素节点插入到链表尾部voidlinkLast(Ee) { // 将最后一个元素赋值(引用传递)给节点 lfinalNode<E> l = last; // 创建节点,并指定节点前驱为链表尾节点 last,后继引用为空finalNode<E> newNode = newNode<>(l, e, null); // 将 last 引用指向新节点last = newNode; // 判断尾节点是否为空// 如果 l 是null 意味着这是第一次添加元素if (l == null) // 如果是第一次添加,将first赋值为新节点,此时链表只有一个元素first = newNode; else// 如果不是第一次添加,将新节点赋值给l(添加前的最后一个元素)的nextl.next = newNode; size++; modCount++; } // 在指定元素之前插入元素voidlinkBefore(Ee, Node<E> succ) { // assert succ != null;断言 succ不为 null// 定义一个节点元素保存 succ 的 prev 引用,也就是它的前一节点信息finalNode<E> pred = succ.prev; // 初始化节点,并指明前驱和后继节点finalNode<E> newNode = newNode<>(pred, e, succ); // 将 succ 节点前驱引用 prev 指向新节点succ.prev = newNode; // 判断前驱节点是否为空,为空表示 succ 是第一个节点if (pred == null) // 新节点成为第一个节点first = newNode; else// succ 节点前驱的后继引用指向新节点pred.next = newNode; size++; modCount++; }LinkedList获取元素相关的方法一共有 3 个:
getFirst():获取链表的第一个元素。getLast():获取链表的最后一个元素。get(int index):获取链表指定位置的元素。
// 获取链表的第一个元素publicEgetFirst() { finalNode<E> f = first; if (f == null) thrownewNoSuchElementException(); returnf.item; } // 获取链表的最后一个元素publicEgetLast() { finalNode<E> l = last; if (l == null) thrownewNoSuchElementException(); returnl.item; } // 获取链表指定位置的元素publicEget(intindex) { // 下标越界检查,如果越界就抛异常checkElementIndex(index); // 返回链表中对应下标的元素returnnode(index).item; }这里的核心在于 node(int index) 这个方法:
// 返回指定下标的非空节点Node<E> node(intindex) { // 断言下标未越界// assert isElementIndex(index);// 如果index小于size的二分之一 从前开始查找(向后查找) 反之向前查找if (index < (size >> 1)) { Node<E> x = first; // 遍历,循环向后查找,直至 i == indexfor (inti = 0; i < index; i++) x = x.next; returnx; } else { Node<E> x = last; for (inti = size - 1; i > index; i--) x = x.prev; returnx; } }get(int index) 或 remove(int index) 等方法内部都调用了该方法来获取对应的节点。
从这个方法的源码可以看出,该方法通过比较索引值与链表 size 的一半大小来确定从链表头还是尾开始遍历。如果索引值小于 size 的一半,就从链表头开始遍历,反之从链表尾开始遍历。这样可以在较短的时间内找到目标节点,充分利用了双向链表的特性来提高效率。
LinkedList删除元素相关的方法一共有 5 个:
removeFirst():删除并返回链表的第一个元素。removeLast():删除并返回链表的最后一个元素。remove(E e):删除链表中首次出现的指定元素,如果不存在该元素则返回 false。remove(int index):删除指定索引处的元素,并返回该元素的值。void clear():移除此链表中的所有元素。
// 删除并返回链表的第一个元素publicEremoveFirst() { finalNode<E> f = first; if (f == null) thrownewNoSuchElementException(); returnunlinkFirst(f); } // 删除并返回链表的最后一个元素publicEremoveLast() { finalNode<E> l = last; if (l == null) thrownewNoSuchElementException(); returnunlinkLast(l); } // 删除链表中首次出现的指定元素,如果不存在该元素则返回 falsepublicbooleanremove(Objecto) { // 如果指定元素为 null,遍历链表找到第一个为 null 的元素进行删除if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); returntrue; } } } else { // 如果不为 null ,遍历链表找到要删除的节点for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); returntrue; } } } returnfalse; } // 删除链表指定位置的元素publicEremove(intindex) { // 下标越界检查,如果越界就抛异常checkElementIndex(index); returnunlink(node(index)); }这里的核心在于 unlink(Node<E> x) 这个方法:
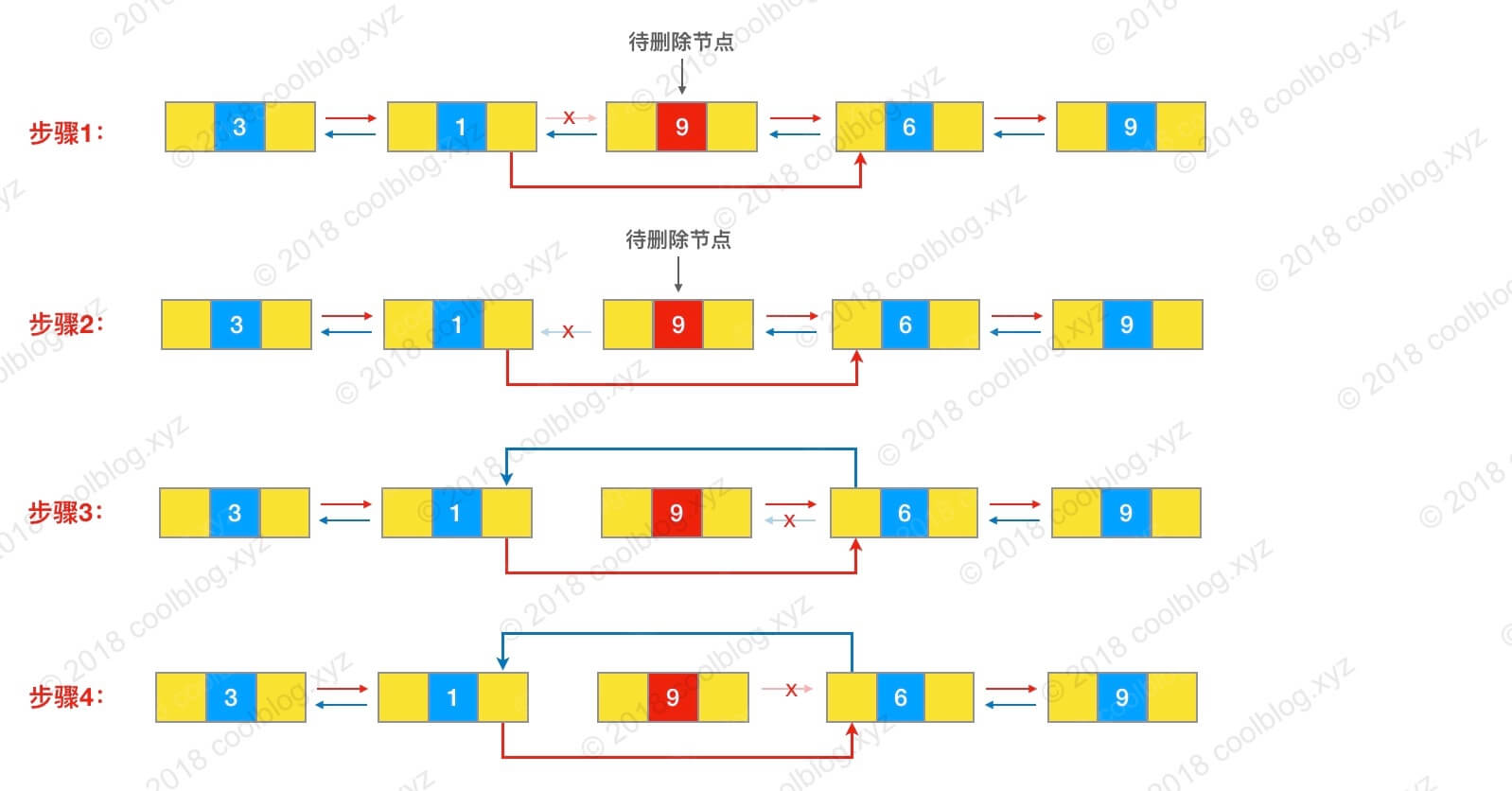
Eunlink(Node<E> x) { // 断言 x 不为 null// assert x != null;// 获取当前节点(也就是待删除节点)的元素finalEelement = x.item; // 获取当前节点的下一个节点finalNode<E> next = x.next; // 获取当前节点的前一个节点finalNode<E> prev = x.prev; // 如果前一个节点为空,则说明当前节点是头节点if (prev == null) { // 直接让链表头指向当前节点的下一个节点first = next; } else { // 如果前一个节点不为空// 将前一个节点的 next 指针指向当前节点的下一个节点prev.next = next; // 将当前节点的 prev 指针置为 null,,方便 GC 回收x.prev = null; } // 如果下一个节点为空,则说明当前节点是尾节点if (next == null) { // 直接让链表尾指向当前节点的前一个节点last = prev; } else { // 如果下一个节点不为空// 将下一个节点的 prev 指针指向当前节点的前一个节点next.prev = prev; // 将当前节点的 next 指针置为 null,方便 GC 回收x.next = null; } // 将当前节点元素置为 null,方便 GC 回收x.item = null; size--; modCount++; returnelement; }unlink() 方法的逻辑如下:
- 首先获取待删除节点 x 的前驱和后继节点;
- 判断待删除节点是否为头节点或尾节点:
- 如果 x 是头节点,则将 first 指向 x 的后继节点 next
- 如果 x 是尾节点,则将 last 指向 x 的前驱节点 prev
- 如果 x 不是头节点也不是尾节点,执行下一步操作
- 将待删除节点 x 的前驱的后继指向待删除节点的后继 next,断开 x 和 x.prev 之间的链接;
- 将待删除节点 x 的后继的前驱指向待删除节点的前驱 prev,断开 x 和 x.next 之间的链接;
- 将待删除节点 x 的元素置空,修改链表长度。
可以参考下图理解(图源:LinkedList 源码分析(JDK 1.8)):
推荐使用for-each 循环来遍历 LinkedList 中的元素, for-each 循环最终会转换成迭代器形式。
LinkedList<String> list = newLinkedList<>(); list.add("apple"); list.add("banana"); list.add("pear"); for (Stringfruit : list) { System.out.println(fruit); }LinkedList 的遍历的核心就是它的迭代器的实现。
// 双向迭代器privateclassListItrimplementsListIterator<E> { // 表示上一次调用 next() 或 previous() 方法时经过的节点;privateNode<E> lastReturned; // 表示下一个要遍历的节点;privateNode<E> next; // 表示下一个要遍历的节点的下标,也就是当前节点的后继节点的下标;privateintnextIndex; // 表示当前遍历期望的修改计数值,用于和 LinkedList 的 modCount 比较,判断链表是否被其他线程修改过。privateintexpectedModCount = modCount; ………… }下面我们对迭代器 ListItr 中的核心方法进行详细介绍。
我们先来看下从头到尾方向的迭代:
// 判断还有没有下一个节点publicbooleanhasNext() { // 判断下一个节点的下标是否小于链表的大小,如果是则表示还有下一个元素可以遍历returnnextIndex < size; } // 获取下一个节点publicEnext() { // 检查在迭代过程中链表是否被修改过checkForComodification(); // 判断是否还有下一个节点可以遍历,如果没有则抛出 NoSuchElementException 异常if (!hasNext()) thrownewNoSuchElementException(); // 将 lastReturned 指向当前节点lastReturned = next; // 将 next 指向下一个节点next = next.next; nextIndex++; returnlastReturned.item; }再来看一下从尾到头方向的迭代:
// 判断是否还有前一个节点publicbooleanhasPrevious() { returnnextIndex > 0; } // 获取前一个节点publicEprevious() { // 检查是否在迭代过程中链表被修改checkForComodification(); // 如果没有前一个节点,则抛出异常if (!hasPrevious()) thrownewNoSuchElementException(); // 将 lastReturned 和 next 指针指向上一个节点lastReturned = next = (next == null) ? last : next.prev; nextIndex--; returnlastReturned.item; }如果需要删除或插入元素,也可以使用迭代器进行操作。
LinkedList<String> list = newLinkedList<>(); list.add("apple"); list.add(null); list.add("banana"); // Collection 接口的 removeIf 方法底层依然是基于迭代器list.removeIf(Objects::isNull); for (Stringfruit : list) { System.out.println(fruit); }迭代器对应的移除元素的方法如下:
// 从列表中删除上次被返回的元素publicvoidremove() { // 检查是否在迭代过程中链表被修改checkForComodification(); // 如果上次返回的节点为空,则抛出异常if (lastReturned == null) thrownewIllegalStateException(); // 获取当前节点的下一个节点Node<E> lastNext = lastReturned.next; // 从链表中删除上次返回的节点unlink(lastReturned); // 修改指针if (next == lastReturned) next = lastNext; elsenextIndex--; // 将上次返回的节点引用置为 null,方便 GC 回收lastReturned = null; expectedModCount++; }代码:
// 创建 LinkedList 对象LinkedList<String> list = newLinkedList<>(); // 添加元素到链表末尾list.add("apple"); list.add("banana"); list.add("pear"); System.out.println("链表内容:" + list); // 在指定位置插入元素list.add(1, "orange"); System.out.println("链表内容:" + list); // 获取指定位置的元素Stringfruit = list.get(2); System.out.println("索引为 2 的元素:" + fruit); // 修改指定位置的元素list.set(3, "grape"); System.out.println("链表内容:" + list); // 删除指定位置的元素list.remove(0); System.out.println("链表内容:" + list); // 删除第一个出现的指定元素list.remove("banana"); System.out.println("链表内容:" + list); // 获取链表的长度intsize = list.size(); System.out.println("链表长度:" + size); // 清空链表list.clear(); System.out.println("清空后的链表:" + list);输出:
索引为 2 的元素:banana 链表内容:[apple, orange, banana, grape] 链表内容:[orange, banana, grape] 链表内容:[orange, grape] 链表长度:2 清空后的链表:[]